

富士通研究所、初めて見る超難解な漢字でも、手書き入力で瞬時に検索
富士通研究所(村野和雄社長)は4月24日、手書き入力で約8万2000字の漢字から瞬時に目的の文字を検索できるシステムを開発したと発表した。
 富士通研究所(村野和雄社長)は4月24日、手書き入力で約8万2000字の漢字から瞬時に目的の文字を検索できるシステムを開発したと発表した。
富士通研究所(村野和雄社長)は4月24日、手書き入力で約8万2000字の漢字から瞬時に目的の文字を検索できるシステムを開発したと発表した。
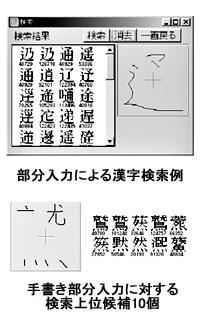
日常ではほとんど目にする機会がなく、読み方もわからないような難しい漢字を簡単に探し出して入力できるようにするシステム。漢字の形をマウスなどで手書きしていくと、「へん」や「つくり」といった漢字を構成する部分の形を手がかりに自動的に当該の漢字を絞り込んでいく。画数や筆順に関わりなく、文字の一部からでも検索できるのが特徴。
これまでは、マウスなどで手書きした図形を文字としてシステムに認識させるには、実際に手書きで入力した筆跡のデータ集めた辞書を使っていた。しかも、書き方や筆順などが人によって異なることもあるため、たくさんの筆記者が書いた手書き文字データを集める必要もあった。しかし、ほとんど書いたことがない、難しい漢字の場合、手書きデータの収集が難しく、その漢字に対応した文字認識辞書を作成することが困難だった。
今回開発した技術では、既存の文字フォントから文字の部品と位置関係だけ抜き出し、抜き出した部品のみにあった手書きデータを集め、それらを組み合わせることで、難しい文字に対応した文字認識辞書を作成することに成功。結果として収集する手書きデータを約40分の1まで減らすことができた。
また該当する文字を探す際、これまでは形の類似性に加え筆順なども加味して検索していたため、筆順が正しくない場合はヒットしないといった問題があった。しかし今回の技術では形の類似性に重点を置いて検索するため、間違った筆順で書いた文字や続け書きの文字でも類似度順に提示し、検索することができるようになった。
同社が行った実験では、全画数を筆記した場合で上位30候補に正解が含まれる率が97.9%。さらに全画数の6割でも58%と、高いヒット率を記録した。また、Pentium4、1.7GHzのPC使用時で、1文字あたり約0.8秒ときわめて短時間での検索も実現した。
同社では今年度、自治体向け戸籍システムや汎用日本語入力ソリューションパッケージにこの技術を搭載する予定としている。
富士通研究所(村野和雄社長)は4月24日、手書き入力で約8万2000字の漢字から瞬時に目的の文字を検索できるシステムを開発したと発表した。日常ではほとんど目にする機会がなく、読み方もわからないような難しい漢字を簡単に探し出して入力できるようにするシステム。漢字の形をマウスなどで手書きしていくと、「へん」や「つくり」といった漢字を構成する部分の形を手がかりに自動的に当該の漢字を絞り込んでいく。画数や筆順に関わりなく、文字の一部からでも検索できるのが特徴。
これまでは、マウスなどで手書きした図形を文字としてシステムに認識させるには、実際に手書きで入力した筆跡のデータ集めた辞書を使っていた。しかも、書き方や筆順などが人によって異なることもあるため、たくさんの筆記者が書いた手書き文字データを集める必要もあった。しかし、ほとんど書いたことがない、難しい漢字の場合、手書きデータの収集が難しく、その漢字に対応した文字認識辞書を作成することが困難だった。
今回開発した技術では、既存の文字フォントから文字の部品と位置関係だけ抜き出し、抜き出した部品のみにあった手書きデータを集め、それらを組み合わせることで、難しい文字に対応した文字認識辞書を作成することに成功。結果として収集する手書きデータを約40分の1まで減らすことができた。
また該当する文字を探す際、これまでは形の類似性に加え筆順なども加味して検索していたため、筆順が正しくない場合はヒットしないといった問題があった。しかし今回の技術では形の類似性に重点を置いて検索するため、間違った筆順で書いた文字や続け書きの文字でも類似度順に提示し、検索することができるようになった。
同社が行った実験では、全画数を筆記した場合で上位30候補に正解が含まれる率が97.9%。さらに全画数の6割でも58%と、高いヒット率を記録した。また、Pentium4、1.7GHzのPC使用時で、1文字あたり約0.8秒ときわめて短時間での検索も実現した。
同社では今年度、自治体向け戸籍システムや汎用日本語入力ソリューションパッケージにこの技術を搭載する予定としている。





